The Qwen team at Alibaba Cloud have recently launched their latest model Qwen2 (Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B). Earlier, they released the Qwen series. As of now it seems that Qwen2 is the best open-source LLM available as of now, the reason being how it surpasses all the other model in almost all benchmarks. Keep reading and you will find out this as the best blog on Qwen2!
![]()
Introduction
Qwen2 is basically the evolution from Qwen 1.5, and it has an extended context length support up to 128K tokens with Qwen2-7B-Instruct and Qwen2-72B-Instruct.
It is trained on 27 additional languages from around the world, besides English and Chinese. Also, in case you don't know, large language models possess an inherent capacity to generalize to other languages. Still, it is required to train them separately on other languages for better results.
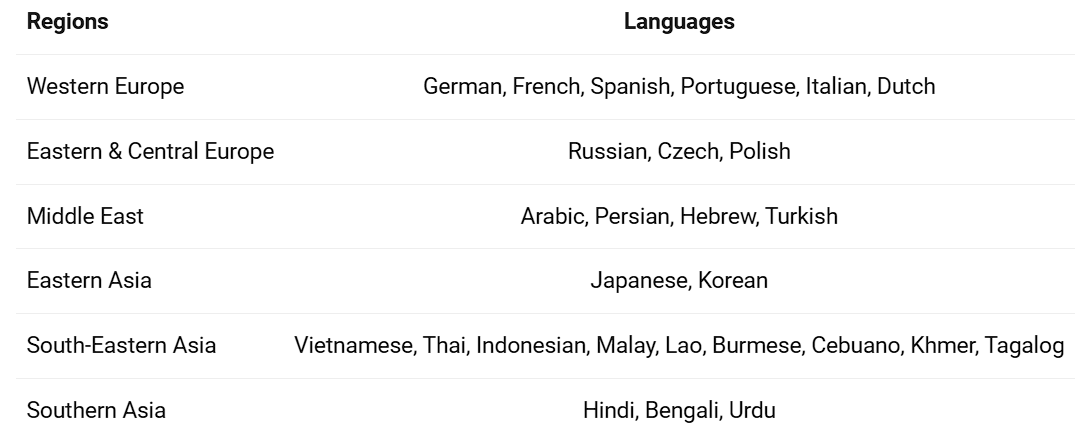
Previously in Qwen1.5, only Qwen1.5-32B and Qwen1.5-110B have adopted Group Query Attention (GQA). This time, for all model sizes they have applied GQA so that these can enjoy the benefits of faster speed and less memory usage in model inference. As of now, the models have been open sourced on Hugging Face and ModelScope.
How can you use & try the models?
All the models have been released on Hugging Face and ModelScope and you can try the Qwen-72B-Instruct model on this Hugging Face Space.
Important Role of Intel
To maximize the efficiency of LLMs, such as Alibaba Cloud's Qwen2, a comprehensive suite of software optimizations is essential, and Intel has supported the Qwen team here. Alibaba Cloud and Intel collaborate in AI software for datacenter, client and edge platforms, fostering an environment that drives innovation, with examples including but not limited to ModelScope, Alibaba Cloud PAI, OpenVINO, and others. As a result, Alibaba Cloud's AI models can be optimized across various computing environments.
Read more on this here.
Performance
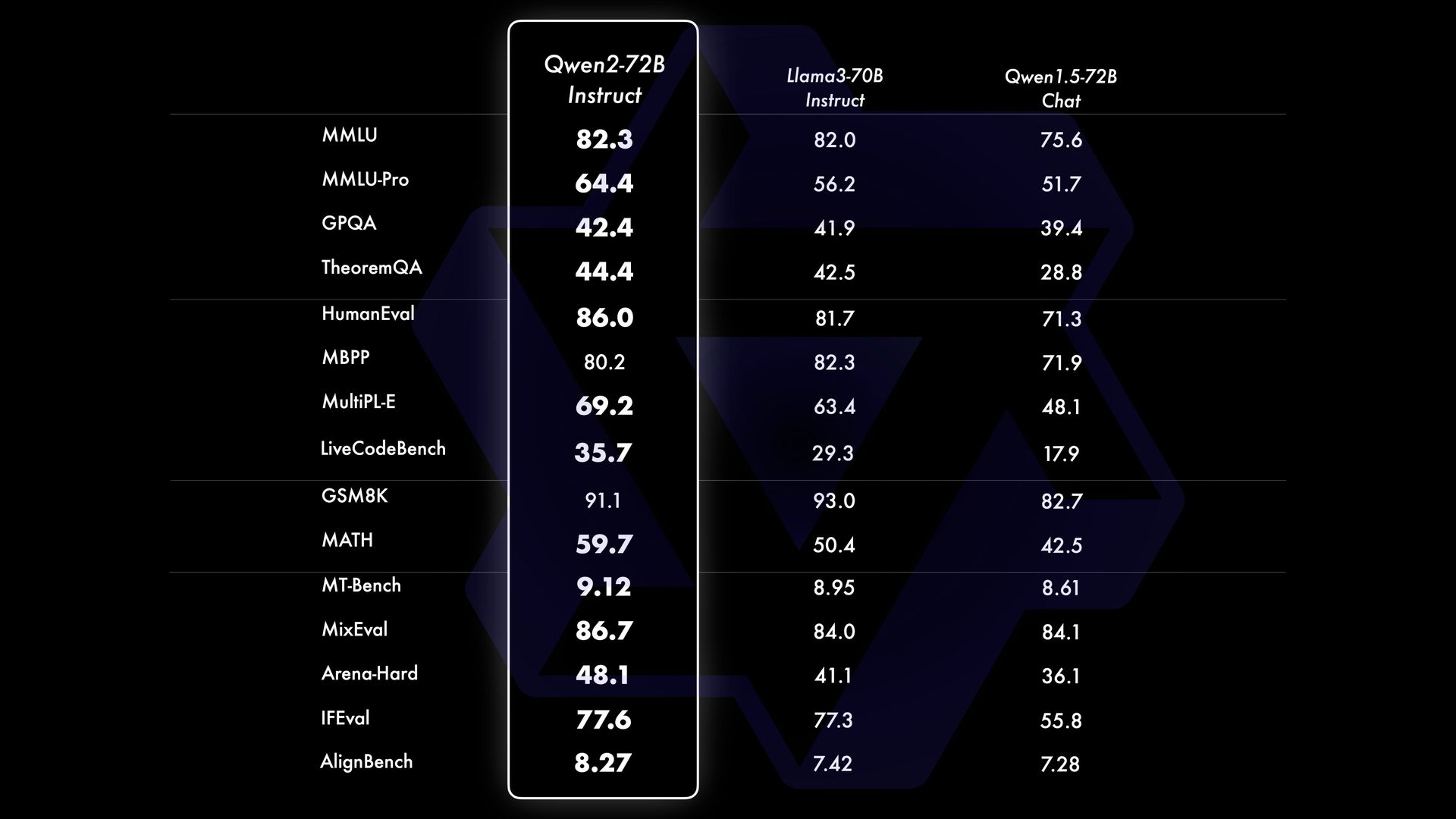
Below are the results (Source: Qwen) of comparison of Qwen2-72B-Instruct with other popular models:
SOTA PERFORMANCE:
Specifically, Qwen2-72B-Instruct significantly surpasses Qwen1.5-72B-Chat across all benchmarks, and also reaches competitive performance compared with Llama-3-70B-Instruct.
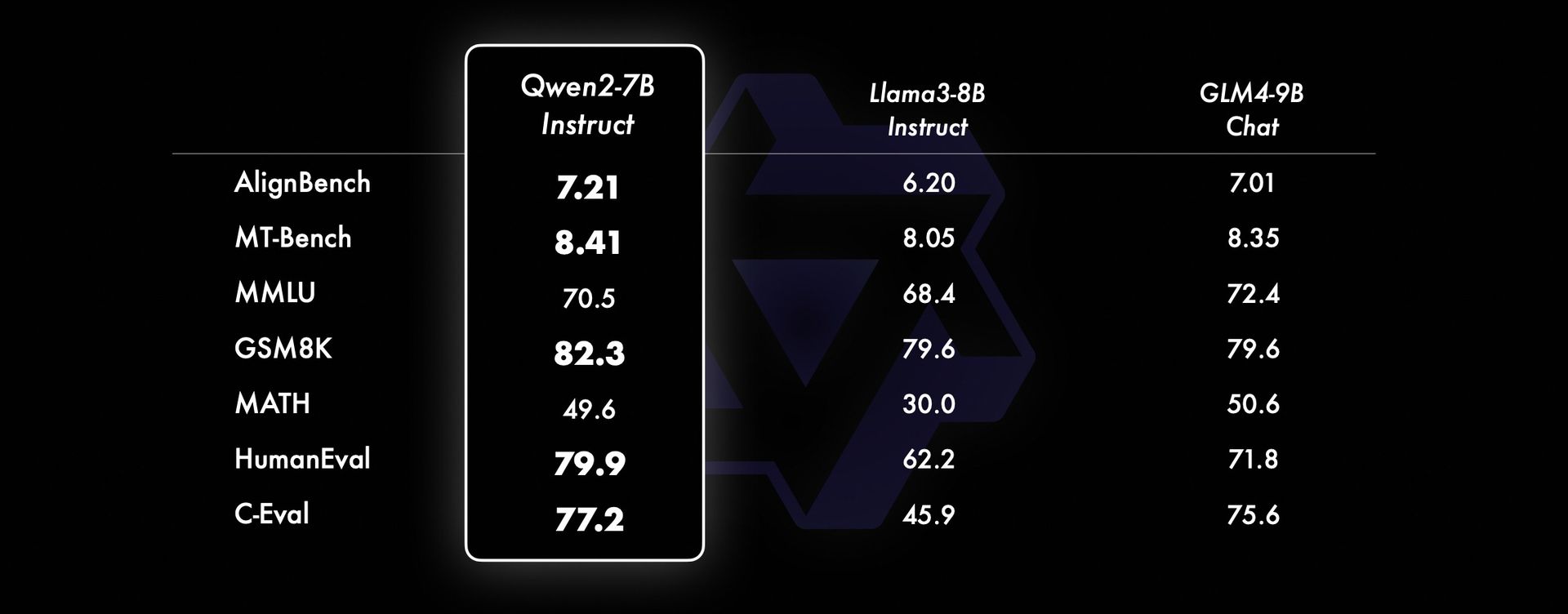
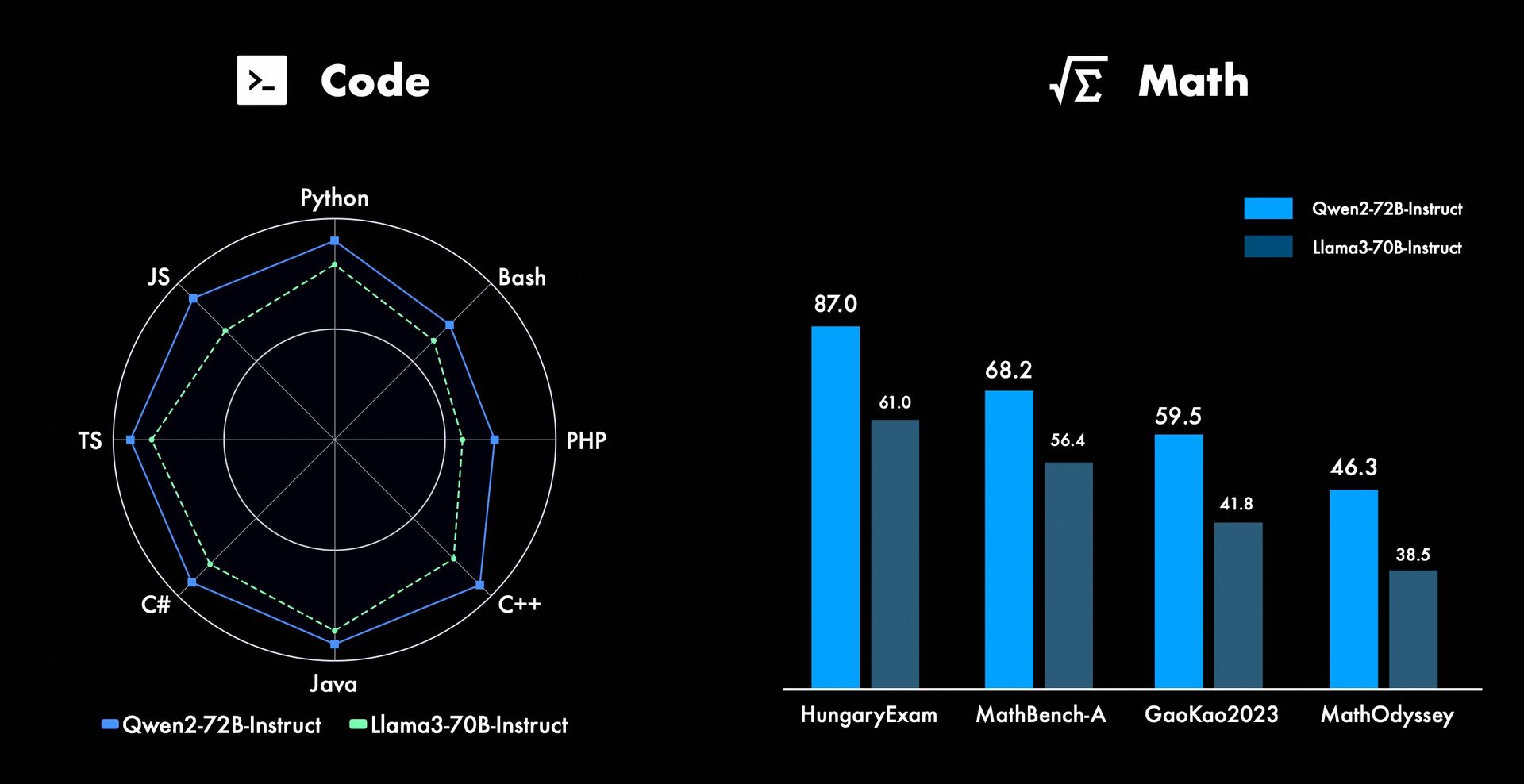
MATHS AND CODING:
These results are really impressive as how this model beats Llama 3 on every benchmark! If you want to know about how Llama 3 performed against ChatGPT, you can read it on this blog.
Additionally, it’s worth noting the impressive capabilities of other models in the series: Qwen2-7B-Instruct nearly flawlessly handles contexts up to 128k in length, Qwen2-57B-A14B-Instruct manages contexts up to 64k, and the two smaller models in the lineup support contexts of 32k.
What really differentiates it from other LLMs?
It seems that one of the main reasons why Qwen2’s performance is so good is because of its post-training, which is conducted after large scale pre-training of the model. Post-training further enhances its intelligence, improving its performance in subjects like coding, mathematics, reasoning, instruction following and multilingual understanding. Additionally, it aligns the model’s output with human values, ensuring that it is helpful, honest, and harmless. The post-training phase is designed with the principle of scalable training with minimal human annotation.
Safety and Responsibility
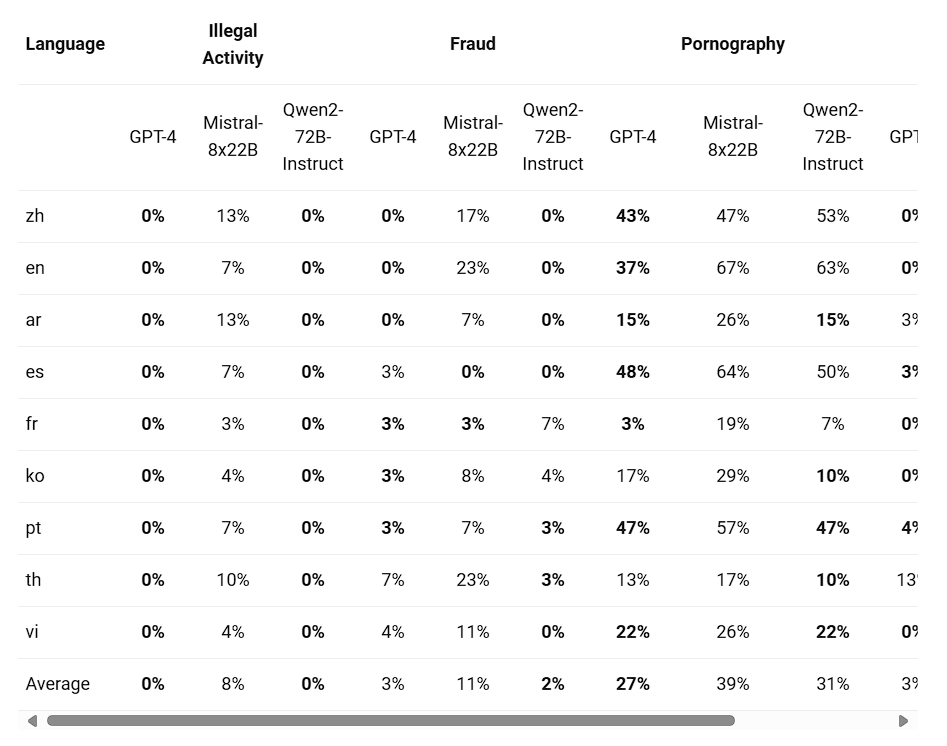
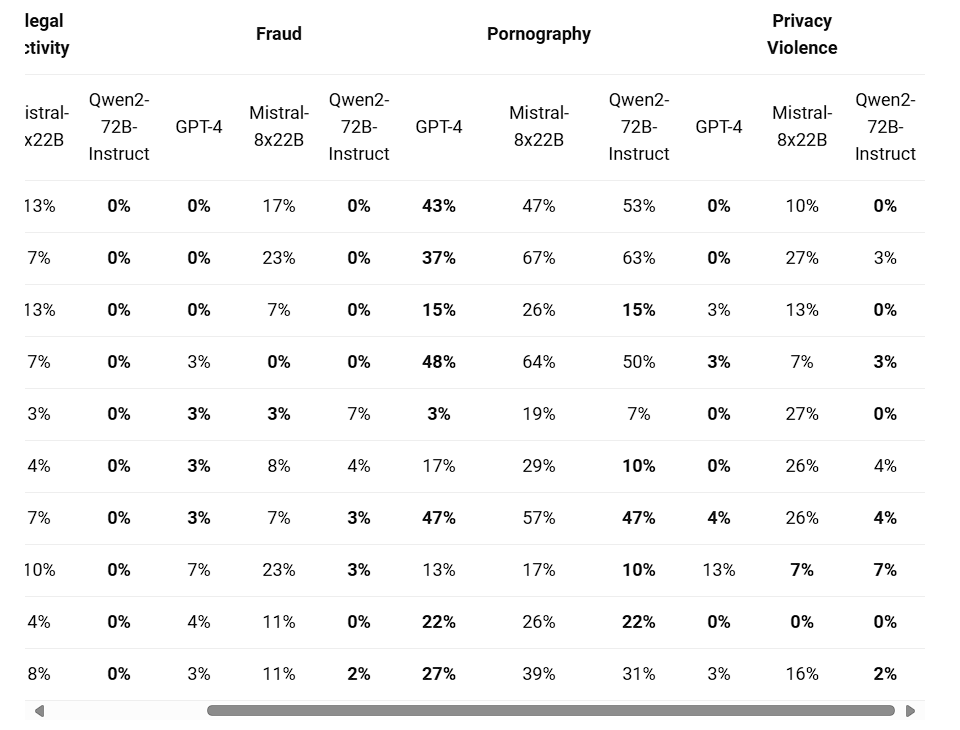
The table below (Source: Qwen) presents the proportion of harmful responses generated by large models for four categories of multilingual unsafe querys(Illegal Activity, Fraud, Pornography, Privacy Violence). The test data was derived from Jailbreak and translated into multiple languages for evaluation. The Qwen team claims they found that Llama-3 does not effectively handle multilingual prompts, and therefore, it is not included in the comparison. Through significance testing (P_value), it was found that the Qwen2-72B-Instruct model performs comparably to GPT-4 in terms of safety, and significantly outperforms the Mistral-8x22B model.
License
Qwen2-72B as well as its instruction-tuned models still uses the original Qianwen License, all other models, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, and Qwen2-57B-A14B, turn to adopt Apache 2.0!
Final remarks
- The results in the SOTA, math and coding tests clearly shows how Qwen2 is a powerful model and outperforms Llama 3.
- This model supports 27 languages, and this makes it accessible to a greater number of users around the world.
- Overall, the model seems good, but we will compare it in-depth soon in some of our upcoming blogs, so stay tuned!
- What’s next? The Qwen team said they are working on training larger Qwen2 models to further explore model scaling.